It has been 20 months to the day since I first arrived at the snow covered Ukraine-Poland border to help refugees. I never expected to cross the border, and I certainly never expected to be as far east as Kharkiv. But here I am, back in Ukraine for what must be my fifth trip this year and maybe tenth overall. I’ve lost count.
We are now entering the third winter of this horrible war, and things have certainly changed in that time — for the war, for us an organization, and for me.
At the beginning, even on the Polish side of the border, the atmosphere was hot and intense. Thousands of refugees poured across the border by the minute, and everyone needed something urgently. I was at the Pryzemysl train station when the first train with Mariupol refugees arrived. Knowing what they had gone through, and hearing their stories — even talking to the ones who couldn’t speak any English — was heartbreaking. They had gone days without food in some cases. They carried their whole lives with them in makeshift baggage.

Now, the war has become the new normal on the home front, so much so that wandering the bustling streets of Kharkiv or Kyiv or Lviv you might not know there even was a war going on, aside from the occasional blackout and the hum of electric generators, high fuel prices, a 10pm curfew, and the occasional wail of air sirens that everyone now ignores. When I first entered Ukraine, it was at 4am after a grueling cross-border journey to deliver my first humanitarian shipment. The mood in Lviv was somber and intense. Now, the cable cars rumble monotonously through the cobbled European streets while children play in the public square. I was here in Kharkiv in June 2022, right after the Russians pulled back from the outskirts of the city, and it was a ghost town, with windows boarded up and rubble and broken glass and spent munitions everywhere. Now, traffic is back, and I had a drink last night at a bustling popular local coffee bar.

The work we are doing as an organization, too, has changed drastically. I and my fellow volunteers, haphazardly organized, uncoordinated and running on adrenaline, worked 18-hour days helping people find transport into Europe, passing out food and water and power banks, sometimes driving six hours to Warsaw and back in one day. Over time, we started organizing volunteers to arrange cross-border shipments. That first summer, I drove humanitarian aid across the border over 40 times, sometimes twice in one day.

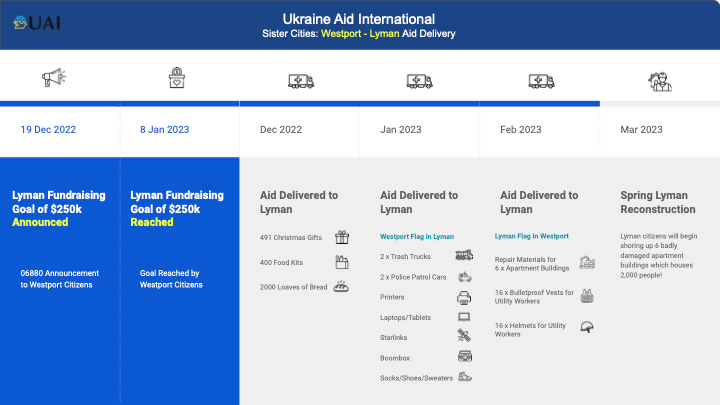
All this while my brother, always the smarter one, was organizing us as a real US-based nonprofit. Donations that used to come into my personal Venmo were now flowing through our new website. We held fundraisers and promoted the work we were doing on social media and amongst friends. Before long, we had a small staff and a collection of international volunteers in the US and Germany and a ground team in Ukraine, and we were working closer and closer to the front lines, where civilians victimized by war needed the most help. By last winter, we had established our first sister city between Lyman, Donetsk and Westport, CT. And 7 other amazing sister city partnerships followed.

Going into this year, we knew that the war would fall behind in public consciousness as more dramatic, fresher stories took center stage. But thousands of civilians on the ground in east Ukraine have still spent the last year without homes, without heat, without electricity, and without infrastructure. And as many basic needs like food and medicine are now being supplied by lots of fantastic NGOs now operating on the ground, municipal needs — things that cities need to keep functioning like utility lines, clean water, and public safety — are still far behind.

That is why UAI is now laser-focused on helping our sister cities’ largest most urgent municipal needs, as we engage our US town partners to supply everything from dump trucks to cold weather gear for our friends in the east. This year alone, thanks to your donations and support, we’ve delivered:
- Clean water access to over 100,000 civilians on the front lines in Ukraine, including two mobile water trucks that operate independently from village to village
- Reconstruction of over 20 apartment buildings with 100s of units, employing local labor and materials
- Enough vegetable seeds for every family in Lyman and Sviatohirsk to replant their farms and gardens after liberation
- Trash trucks, dump trucks, ambulances, squad cars and delivery vans to support communities of more than 25,000 residents
- Equipment for hundreds of first responders including flashlights, socks, boots, tools, cold weather gear
- Hundreds of stoves, electric generators, internet access, school supplies, blankets, medical and reconstruction aid
- One (and soon to be more!) wood pellet production machine to provide enough fuel to heat 1,000 homes delivered just in time for winter
All of this would not have been possible without the steadfast dedication and support of our Sister City Committees, who, for every town in our program, worked tirelessly to raise awareness and fundraise for our friends in Ukraine. These programs have shown how people can come together to help complete strangers in a time of need, and have been inspiring. If you served on a Sister City Committee or volunteered to help at one of our local fundraising events, thank you.

Finally, on a personal note. This has been a challenging year, and I’ve learned a lot. Cofounding a nonprofit and growing it from the ground up has not been easy, and I’ve stumbled into many hard lessons along the way. I’ve been around long enough to know that there’s a moment in every project where it ceases to be shiny, new and exciting, and becomes just another regular job. However, rather than let UAI stultify as I may have if it were any other project, it has been my honor and privilege to watch our team grow, evolve and blossom over the last 20 months. I owe a huge debt to my brother and cofounder, Marshall, who has led this team through major ups and downs this year. Our little fledgling charity has reached a point where I have discovered — as many founders often do — that I am not even needed by my team for most things. Which is an amazing feeling! At the same time, it has given me excitement to think forward to next year, and the type of global community we want to build around sister cities and mutual aid. I can’t wait to share those plans with all of you soon.

This year would not have been possible without our dedicated and hard working team: Alison, Bogdan, and Nikita, running all our operations and logistics inside Ukraine, the unstoppable Ally in Germany who has organized all our Sister City Committees remotely with hundreds of thousands of dollars raised since day one, Katya and Nataliia in Connecticut running the entire home office, and our newest addition as of this month, welcome to Karianne in Chicago who is now running our marketing! And so many other great volunteers, friends and partners we’ve worked with all year to deliver aid and support to civilians in need:
- In Ukraine: Yaroslav, Ruslan, Alona, Svitlana, Ron, Nick, Vitaly, Evgeniya, Nate, Ben, Paul, Vlada, Brogan, Vova, Andrii, and Serhii, and countless more who took hours or days out of their lives to help with missions all around the country
- Our international friends, honored representatives and nonprofit partners: Senator Blumenthal, Congressman Himes, State Senator Maher, Ken, Dan, Connie, Jessie, Olga, Annetta, Ben, Greg
- Our groundbreaking US delegation to Donetsk Oblast: Jen Tooker, First Selectwoman of Westport CT, David Bindelglass, First Selectman of Easton CT, Foti Koskinas, Chief of Police of Westport CT
- Our honored US Mayors and First Selectpeople: Caroline Simmons (Stamford CT), Fred Camillo (Greenwich CT), Tonya Graham (Ashland OR), Brenda Kupchick (Fairfield CT), Rudy Marconi (Ridgefield CT), Samantha Nestor (Weston CT), Darrell Steinberg (Sacramento CA)
- …and so many others I’m probably doing a disservice to by neglecting to list here, and I’m sorry! It truly has been a team effort.
Finally, all of this would not have been possible without all of you, our donors and supporters. I know that there are a lot of important causes where you could be contributing your support, and you’ve chosen to help the Ukrainian people all year. On their behalf, and on behalf of the dedicated team at UAI, thank you, and have an amazing holiday and New Year!