Projects
-
Let’s say you have a table of the format: Where each entry, for simplicity’s sake, is one change in boolean status for the object: TRUE | FALSE or FALSE | TRUE. This is a fairly common history table that you’d find in the database of many applications, for example a profile settings history with a…
-
I took a stab at making my own crossword puzzle, complete with thematic clues and even thematic grid shapes to match. Have fun, and if you want the solution, drop a note in the comments. Across 1. Battleship, for example 5. Like hydrochloric and nitric 9. Chit chat 12. Madison and Park, e.g. 13. Paradise…
-

I have been relatively silent recently regarding ReservationHop. We have been doing a lot of exploration (or in startup lingo, “customer discovery”) as we try to find a good niche for innovation in restaurants that benefits consumers and optimizes some part of the dining experience. Consequently, in the last couple of months, we have built and…
-
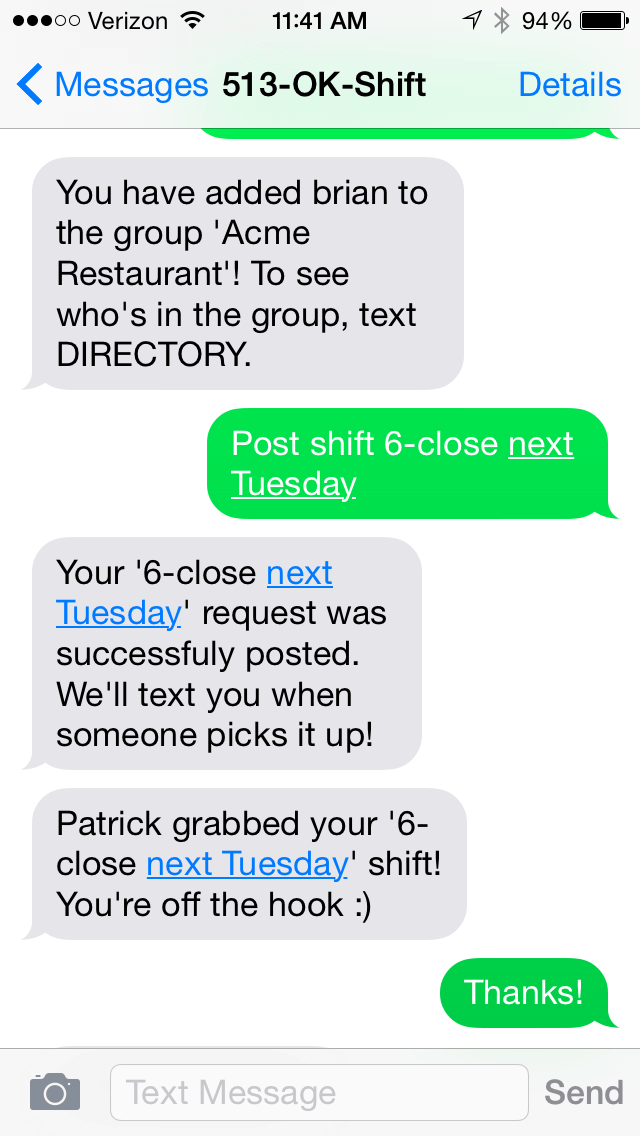
The idea was simple: why isn’t there a good system for hourly workers (60% of the US workforce) to swap their shifts out via text message? Enter OK Shift, a text message-only based system that allows hourly workers to swap their shifts via text message, and get those swaps approved by managers. The system allows…
-

Why is the API model traditionally built around a central entity node connected to many consumer nodes, rather than the other way around? Why is it possible for me to connect with various APIs from cloud services like Twilio and Dropbox but I can’t create an API for myself that allows companies to connect with…
-

I took a break from ReservationHop today to build a new chat program. EphChat, which stands for, you guessed it, “Ephemeral Chat,” is a chat program with a twist. No data is stored server side, and messages are only visible to participants for 60 seconds before they fade away into nothingness. Anyone can create a…
-
It has been a crazy holiday weekend. In three days we went from relative obscurity to being the punching bag of the entire tech industry. I suppose some might envy me for all the media attention I’ve received for a side project I built in my underwear one night after waiting in line for a…
-

This morning I put the finishing touches on, and launched, ReservationHop.com, a site where I’m selling reservations I booked up at hot SF restaurants this Fourth of July weekend and beyond. I built it over the weekend after waiting at Off the Grid for 30 minutes for a burrito from Señor Sisig, and realized that there’s…
-

The genesis of this idea was a couple weeks ago when my cofounder said: “Would it be possible to see what percent of our email list was female or male based on their names alone?” Thus Drillbit was born. In the last couple weeks I have been pouring over data sets and trying different formulas…
-

You may have read the article in the New Republic last month about how 300,000 ancient books and manuscripts in the libraries of Timbuktu were evacuated in secret to protect them from Ansar Dine, an Al Qaeda cell. The manuscripts not only survived the burning of the Timbuktu library, but were smuggled in footlockers all…
